15.10.2008
Base de datos
SQL Server 2008 admite un nuevo de tipo de datos, HierarchyID, que ayuda a resolver algunos de los problemas al modelar y consultar información de jerarquía. Le presentaré este tipo de datos centrándome en un modelo que normalmente se emplea en el sector fabricante y que es conocido como lista (o listas) de materiales. Comenzaré por una breve explicación de las listas de materiales y describiré cómo se puede modelar este tipo de datos. También voy a presentar una implementación de este modelo en SQL Server 2005. Después le mostraré la manera en que se puede usar el tipo de datos HierarchyID para implementar el modelo en SQL Server 2008.
Datos jerárquicos
Los automóviles son el resultado de la unión de muchos componentes, como motores, cigüeñales, sistemas electrónicos y la dirección. En Estados Unidos, nuestros territorios geográficos se dividen en Estados y se subdividen en jurisdicciones denominadas condados. Los condados los subdividen a su vez distintas autoridades de diferentes maneras. La Oficina del Censo de Estados Unidos, por ejemplo, los estructura a partir de distritos de censo. El servicio de correos de Estados Unidos es capaz de entregar correo gracias a los códigos ZIP (códigos postales). Los sistemas de información geográfica (GIS) pueden agregar distritos de censo y códigos postales para ofrecer a los usuarios una referencia espacial familiar para un área.
Durante una visita reciente a una tienda local de electrónica para evaluar un nuevo sistema de entretenimiento doméstico observé un sistema jerárquico parecido: pensar en todas las combinaciones de componentes y opciones posibles me dejó aturdido. Me preguntaba cómo se podrían modular dichos sistemas e implementarlos en un sistema de base de datos.
La relación entre un automóvil y su motor representa una jerarquía: el automóvil contiene el motor. La relación es la misma para el cigüeñal, el sistema electrónico y la dirección. La relación es de contención. Se puede observar una jerarquía semejante en la relación entre los diferentes grupos de datos censales y geográficos.
Las jerarquías existen en todas partes; aún así, implementarlas en el contexto de una base de datos relacional constituye a menudo un desafío. Un enfoque típico es representar la jerarquía que usa una relación primario/secundario con una o más tablas. Si bien es cierto que este enfoque funciona en muchos casos, tiene algunas limitaciones. En tales soluciones, de hecho, se debe prestar especial atención a la manera en que se mantendrá la integridad referencial. Y mientras que la consulta de la profundidad y amplitud de dichas tablas se simplificó considerablemente en SQL Server 2005 con la introducción de expresiones de tabla comunes y recursivas, la creación de consultas para estos tipos de tablas todavía puede resultar problemática cuando son necesarias uniones para muchas tablas.
Problema de la lista de materiales
Hace unos años trabajaba en un sistema que estaba desarrollando una compañía fabricante para ayudar a sus distribuidores a especificar los componentes necesarios para crear sistemas de irrigación de pivote central. El software creó una lista de componentes necesarios para personalizar el pivote deseado (dentro del sector industrial, al sistema de irrigación de pivote central se le denomina sencillamente "pivote"). Los componentes necesarios se determinaron basándose en la geografía, el tipo de suelo y los cultivos que se deseaban plantar en las áreas que se iban a cubrir, así como en función de las consideraciones hidrológicas y estructurales del propio dispositivo.
En la base de la solución propuesta estaría una base de datos de SQL Server. La finalidad de la base de datos fue almacenar información acerca de los componentes disponibles para crear el pivote. Sin embargo, cuando generamos la especificación para fabricar, necesitamos identificar dichos componentes como listas de materiales.
Algunas representaban una recopilación de partes físicas que se ensamblarían en un componente del sistema. Por ejemplo, cada pivote necesitaba una bomba para bombear agua de un pozo al sistema. Esa bomba puede alimentarse con energía eléctrica, por lo que además se necesitará un transformador y una caja de fusibles. O la bomba puede funcionar con combustible, con lo que necesitará un depósito, un surtidor de gasolina y mangueras para conectar la bomba al depósito. En cualquier caso, las partes necesarias para la bomba se enumerarían en la lista de materiales de la bomba.
La lista de un pivote completo incluiría una recopilación de otras listas. Por ejemplo, un pivote estandardizado puede estar compuesto por un árbol de listas para la bomba, otro árbol de listas para las extensiones de tuberías empleadas para abastecer agua, y listas para cualquier otro equipo necesario para crear ese sistema de pivote.
Uso de las entidades para comprender el problema
La primera pregunta de por sí es: ¿cuáles son las entidades de las que debería ocuparse al representar un sistema jerárquico y qué atributos podrían tener dichas entidades? El truco consiste en no perderse en la semántica de los elementos individuales que componen el sistema subyacente que está tratando de modelar.
Por ejemplo, piense en el caso del sistema de centro de entretenimiento basado en PC que se muestra en la Figura 1. Quizás sea fácil decir que cada elemento que se muestra aquí representa una entidad. A pesar de que esto es cierto, resulta difícil representar todos los sistemas de entretenimiento posibles que una compañía podría vender. ¿Qué ocurre si algunos sistemas usan una grabadora de vídeo digital (DVR) en lugar de un PC? ¿Qué ocurriría si los consumidores no desearan un sintonizador de radio?
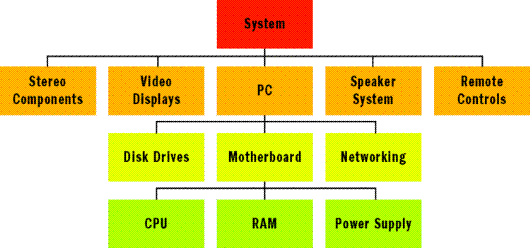
Figura 1. Componentes dentro de un sistema de entretenimiento.
Variaciones como esta son precisamente el motivo por el que un sistema de lista de materiales funciona como modelo para los problemas de modelado de datos jerárquicos. Permite que un sistema completo se componga de diferentes sublistas, y sublistas de otras sublistas, hasta llegar a partes individuales de una estructura de datos de árbol. En la raíz del árbol se encuentra un sistema completo representado por una sola lista. El primer nivel de las ramificaciones también suele estar compuesto por listas. La lista de sublistas continúa bajando por la jerarquía hasta que una lista consta únicamente de un conjunto de partes físicas del sistema, y estas partes se convierten en nodos de hoja del árbol.
Por tanto, ¿qué entidades tenemos en el sistema? Hay listas de materiales que sólo contienen partes (listas de partes) y hay listas de materiales que contienen otras listas.
Una parte tiene una descripción y un costo. (Por supuesto, podría tener muchos otros atributos, pero vamos a simplificar las cosas por motivos ilustrativos). Los atributos de una lista de partes pueden incluir una parte y la cantidad necesaria de dicha parte. Es importante separar la cantidad de una parte concreta de la información sobre esa misma parte. Si no lo hace, puede acabar teniendo muchas instancias duplicadas de una parte basada sólo en la diferencia de la cantidad utilizada. Las reglas de normalización sugieren que esta solución no es adecuada en la mayoría de los casos.
Una lista de materiales deberá tener una descripción, una manera de asociarla a su lista de materiales primaria y una lista de partes asociadas. La Figura 2 representa el conjunto de entidades y sus relaciones.
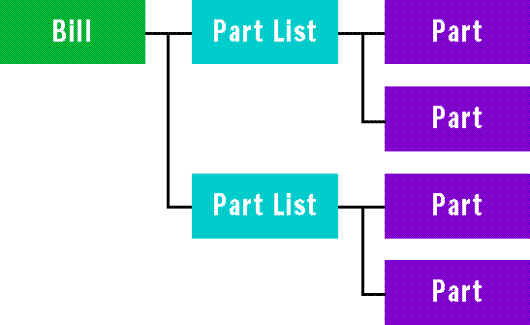
Figura 2. Relación de entidades.
Aunque las bases de datos relacionales son de gran utilidad a la hora de representar la mayoría de las relaciones, no son apropiadas para trabajar con modelos de entidad de varios a varios. No se trata de que las tablas físicas no puedan administrar los datos, sino que resulta difícil crear restricciones referenciales de integridad adecuadas entre las tablas. Dichas relaciones también conllevan consultas complejas. Sin embargo, este problema es fácil de corregir cuando considera primero el diseño lógico de las tablas. En este caso es necesario insertar una tabla entre la tabla de lista de partes y la tabla de lista de materiales. Dicha tabla mantendrá simplemente una referencia a una lista de materiales y una referencia a una lista de partes. La Figura 3 muestra un diagrama de relaciones de entidad que incluye esta tabla adicional.
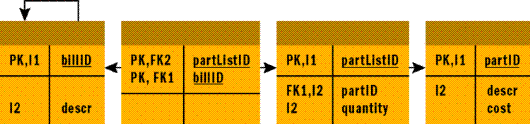
Figura 3. Diagrama de relaciones de entidad para un sistema de lista de materiales simplificado.
Sistema de lista de materiales en SQL Server 2005
Ahora que ha visto la teoría que sostiene un sistema de lista de materiales, es hora de implementar uno. El procedimiento es sencillo.
1. Crear la base de datos
2. Crear las tablas que se muestran en el diagrama de relaciones de entidad
3. Agregar las restricciones necesarias en la tablas adecuadas
4. Configurar permisos de acceso a las tablas según sea necesario
5. Rellenar las tablas con datos de prueba
6. Escribir y ejecutar consultas con las tablas para validar el diseño
He aquí el código de T-SQL para crear una base de datos de ejemplo. Probablemente tendrá que cambiar las rutas de acceso a los nombres de archivo para usarlo en su sistema:
<MTJ_C&P_1>
create database [dbBom] on primary (
name = n'dbBom', filename = n'c:\msdnmag\dbBom.mdf',
size = 50mb , maxsize = unlimited, filegrowth = 2mb )
log on (
name = n'dbBom_log', filename = n'c:\msdnmag\dbBom_log.ldf',
size = 10mb , maxsize = 2048gb , filegrowth = 10%);
Una vez que haya ejecutado correctamente esta instrucción, asegúrese de cambiar el ámbito de la base de datos a dbBOM, como con una instrucción USE dbBOM.
Creación de tablas
Lo siguiente es el código T-SQL ejecutable para crear las cuatro tablas que se necesitan:
<MTJ_C&P_2>
create table dbo.part(
partID smallint not null,
descr varchar(50) not null,
cost money not null);
create table dbo.partList(
partListID int not null,
partID smallint not null,
quantity smallint not null);
create table dbo.billPartList(
billID int not null,
partListID int not null);
create table dbo.bill(
billID int not null,
parentBillID int null,
descr varchar(50) not null);
Tenga en cuenta que la única columna de estas tablas que puede tener un valor nulo es parentBillID en dbo.bill. Este valor nulo nos permite distinguir una lista de materiales que representa un sistema completo de otras listas.
El elemento clave para garantizar la validez referencial de esta implementación es obtener las restricciones de las tablas correctas. Las tablas de la solución tienen funciones diferentes, por lo que tendrán restricciones diferentes. Sin embargo, cada tabla de SQL Server debe tener asociada una clave principal, tal como se indica a continuación:
<MTJ_C&P_3>
alter table dbo.part
add constraint pkPart
primary key clustered(partID);
alter table dbo.bill
add constraint pkBill
primary key clustered(billID);
alter table dbo.partList
add constraint pkPartList
primary key clustered(partListID);
alter table dbo.billPartList
add constraint pkBillPartList
primary key clustered(billID,partListID);
Algunas de estas columnas deberían tener siempre un valor exclusivo, tal como la descripción (descr) de una parte o lista. También puede impedir a los usuarios crear lo que equivale a una entrada duplicada de la lista de partes al exigir la combinación de un identificador de parte y la cantidad necesaria de dicha parte:
<MTJ_C&P_4>
alter table dbo.part
add constraint uqDescr
unique(descr);
alter table dbo.bill
add constraint uqBill
unique(descr);
alter table dbo.partList
add constraint uqPartList
unique(partID,quantity);
Por último, agregue las restricciones de claves externas entre las tablas. La primera restricción se encuentra entre dbo.part y dbo.partList. Esto requerirá que la parte que se está agregando a la lista de partes se defina primero en la tabla dbo.part. Si se elimina una parte de dbo.part, este cambio se debe reflejar en la lista de partes. Para ello, se agrega la cláusula "on delete cascade" a la restricción. Puesto que partID está marcado como identificador, no se puede cambiar y, por tanto, no se debería llevar a cabo ninguna acción en cascada:
<MTJ_C&P_5>
alter table dbo.partList
add constraint fkPartList_Part
foreign key(partID)
references dbo.part(partID)
on delete cascade
on update no action;
La restricción siguiente requiere que si se asigna una lista a un parentBillID, la lista a la que hace referencia billID también debe existir en la tabla dbo.bill. Las restricciones en cascada son diferentes. Aquí está prohibido tener una restricción en cascada porque SQL Server no puede garantizar que tendrá lugar una recursión infinita de acciones cuando se elimine o actualice una lista primaria. Puesto que no se han definido valores predeterminados, la opción "set default" no está disponible.
<MTJ_C&P_6>
alter table dbo.bill
add constraint fkBill_Bill
foreign key(parentBillID)
references dbo.bill(BillID)
on delete no action
on update no action;
La tabla billPartList requiere un par de restricciones de clave externa. En primer lugar, se debe exigir la existencia de la lista de partes asociada a una lista en la tabla PartList. Además, la lista a la que se hace referencia debe incluirse en la tabla dbo.bill. Puesto que ni billID de dbo.bill ni partListID de dbo.partList se pueden actualizar, no hay ninguna acción de cascada posible para las restricciones. Sin embargo, si se elimina una parte o una lista, dichos cambios pueden afectar a esta tabla:
<MTJ_C&P_7>
alter table dbo.billPartList
add constraint fkBillPartList_PartList
foreign key(partListID)
references dbo.partList(partListID)
on delete cascade
on update no action;
alter table dbo.billPartList
add constraint fkBillPartList_Bill
foreign key(billID)
references dbo.bill(billID)
on delete cascade
on update no action;
Ahora puede insertar algunos datos en las tablas para realizar pruebas. Dada la cantidad de datos implicados, no mostraré aquí el código para ello. Si descarga el código de ejemplo para este artículo, simplemente abra y ejecute el script denominado 01_data.sql para generar estos datos de ejemplo.
Consultas para validar el diseño
La escritura y la ejecución de algunas consultas sencillas ayudarán a probar y validar que el diseño funcione de la manera esperada. Mi primera consulta usa la nueva sintaxis de expresiones de tabla comunes para producir un listado jerárquico de listas:
<MTJ_C&P_8>
with c as (
select billID,parentBillID,descr,0 as [level]
from dbo.bill b
where b.parentBillID is null
union all
select b.billID,b.parentBillID,
b.descr,[level] + 1
from dbo.bill b join c on b.parentBillID =
c.billID)
select descr,[level],billID,parentBillID
as bill
from c
En los datos devueltos que se muestran en la Figura 4, hay un único nodo raíz (donde el parentBillID es nulo). Si tuviese más de una lista de este tipo, necesitaría modificar la consulta para seleccionar ese elemento primario según el identificador de la lista.
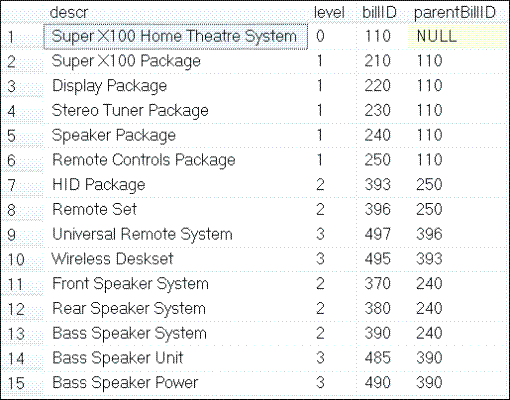
Figura 4. Consulta de una jerarquía de listas.
La consulta siguiente se basa en la primera al enumerar cada una de las partes usadas para la lista de sistema devuelta por la primera consulta. Esta consulta lleva a cabo todas las relaciones entre las tablas:
<MTJ_C&P_9>
with c as (
select billID,parentBillID,descr,0 as [level]
from dbo.bill b
where b.parentBillID is null
union all
select b.billID,b.parentBillID,b.descr,[level] + 1
from dbo.bill b join c on b.parentBillID = c.billID)
select p.partID,p.descr
from c
join dbo.billPartList bpl on c.billID = bpl.billID
left join dbo.partList pl on bpl.partListID = pl.partListID
join dbo.part p on pl.partID = p.partID
group by p.partID,p.descr;
La siguiente consulta calcula el precio de venta recomendado por el fabricante (MSRP) para el sistema al sumar el costo de las partes de sistema necesarias y multiplicándolas por 2:
<MTJ_C&P_10>
with c as (
select billID,parentBillID,descr,0 as lvl
from dbo.bill b
where b.parentBillID is null
union all
select b.billID,b.parentBillID,b.descr,lvl + 1
from dbo.bill b join c on b.parentBillID = c.billID)
select SUM(p.cost*pl.quantity) * 2.0
from c
join dbo.billPartList bpl on c.billID = bpl.billID
left join dbo.partList pl on bpl.partListID= pl.partListID
join dbo.part p on pl.partID = p.partID
La siguiente consulta invierte las consultas anteriores. En vez de atravesar los datos de manera descendente desde la primera lista primaria, se puede observar que empieza por una parte, consulta la lista a la que ésta pertenece y luego va hacia arriba para buscar todas las listas que usan la parte:
<MTJ_C&P_11>
with c as (
select b.descr,b.billID,b.parentBillID,0 as lvl
from dbo.partList pl
left join dbo.billPartList bpl on pl.partListID = bpl.partListID
left join dbo.bill b on bpl.billID = b.billID
where pl.partID = 19
union all
select b.descr,b.billID,b.parentBillID,lvl+1
from dbo.bill b
join c on c.parentBillID = b.billID)
select * from c;
Visualizar la manera en que las listas se relacionan entre sí mediante la lista basada en filas puede resultar difícil. En dichos casos, tiene sentido organizar las listas en rutas de acceso, tal como se muestra a continuación. Al hacerlo, puede ver con facilidad el anidado de las listas:
<MTJ_C&P_12>
with c as (
select '/'+cast(billID as varchar(49)) as path,BillID
from dbo.bill b
where b.parentBillID is null
union all
select cast(c.path+'/'+CAST(b.billID as varchar(4)) as varchar(50)), b.billID
from dbo.bill b join c on b.parentBillID = c.billID)
select c.path+'/',b.descr
from c join dbo.bill b on c.billID = b.billID
order by 1;
Puede consultar el nido resultante en la Figura 5.
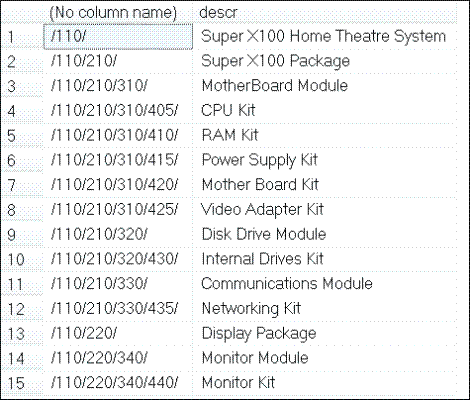
Figura 5. Listado de las listas de materiales anidadas.
Las consultas restantes demuestran la adición de una lista nueva al sistema; en este caso, se debe suponer que la compañía incluye un Memory Stick de 4 GB como parte de la promoción de verano. El código de <MTJ_C&P_13> inserta en la jerarquía una parte nueva y la lista que la representa.
<MTJ_C&P_13>
Inserción de una parte nueva y una lista.
begin transaction
declare @mp int;
declare @mpl int;
declare @mb int;
select @mp = MAX(partID)+10 from dbo.part;
insert into dbo.part(partID,descr,cost)
output inserted.*
values (@mp,'4GB USB 2.0 Memory Stick',20.0);
select @mpl = MAX(partListID)+10 from dbo.partList;
insert into dbo.partList(partListID,partID,quantity)
output inserted.*
values (@mpl,@mp,1);
select @mb = MAX(billID)+10 from dbo.bill;
insert into dbo.bill(billID,parentBillID,descr)
output inserted.*
values (@mb,110,'Summer Bonus Package')
insert into dbo.billPartList(billID,partListID)
output inserted.*
values (@mb,@mpl);
commit;
go
select * from dbo.bill where parentBillID = 110;
select * from dbo.part;
go
Supongamos que ahora alguien indica que la lista de promoción de verano "Summer Bonus Package" no debería encontrarse directamente bajo la lista de sistema total, sino bajo el módulo Disk Drive. Este es un cambio fácil de realizar en una base de datos relacional:
<MTJ_C&P_14>
update dbo.bill set parentBillID = 320 where billID = 507
go
select * from dbo.bill where parentBillID = 320;
go
Al final del período de promoción de verano, la eliminación de esta nueva lista resulta también sencilla:
<MTJ_C&P_15>
begin transaction
delete from dbo.billPartList where billID=507;
delete from dbo.bill where billID=507;
delete from dbo.part where partID=45;
commit;
go
select * from dbo.billPartList;
select * from dbo.bill;
Cómo sacar el máximo partido de HierarchyID
El tipo de datos HierarchyID es una representación binaria basada en CLR que está diseñada para almacenar una representación compacta y binaria de una ruta de acceso ordenada. Puesto que se trata de un tipo de datos integrado, no es necesario activar de manera específica la funcionalidad de SQL/CLR para usarlo. HierarchyID resulta de utilidad siempre que tenga que representar una relación anidada entre valores en los que dicha relación se pueda expresar en una sintaxis de ruta de acceso ordenada.
Una ruta de acceso ordenada tiene el aspecto de una ruta de acceso de archivo, pero en lugar de usar los nombres de directorio y archivo, se usan valores numéricos. Como cualquier otra relación de elemento primario/secundario, todas las rutas de acceso ordenadas se deben delimitar mediante un nodo raíz. En SQL Server 2008, se usa un solo carácter (/) para representar textualmente el nodo raíz. Los elementos con la ruta de acceso ordenada suelen representarse mediante enteros, pero también se pueden usar valores decimales. La ruta de acceso ordenada debe terminar con otro carácter único (/).
Sin embargo, las rutas de acceso ordenadas no se almacenan en la base de datos como texto. En cambio, se les aplica matemáticamente un algoritmo hash para obtener valores binarios, que se almacenarán en las páginas de datos.
Entonces, ¿cómo se debe modificar la base de datos existente para usar HierarchyID? La Figura 6 muestra algunas de las rutas de acceso ordenadas usadas por la lista de ejemplo. Puesto que la relación de elemento primario/secundario en los datos de ejemplo se encuentra en la tabla de listas, ése es un lugar lógico por el que empezar. En lugar de modificar dicha tabla, agregaré una tabla nueva denominada bill2.

Figura 6. Rutas de acceso usadas en la lista de materiales de ejemplo.
Agregaré una columna denominada billPath, del tipo HierarchyID. En esta columna almaceno las relaciones de elemento primario/secundario entre listas, usando el formato ordenado de ruta de acceso. Y aunque puedo en este punto eliminar una columna para navegar a una fila primaria, tener esta capacidad todavía será de utilidad en muchas consultas. Sin embargo, en lugar de almacenar el identificador primario como campo de datos estático, le mostraré cómo puede usar una columna calculada y guardada según el identificador de jerarquía para este tipo de navegación. El código actualizado para la creación de la tabla es el siguiente:
<MTJ_C&P_16>
create table dbo.bill2(
billPath HierarchyID not null,
billID smallint not null,
parentBillPath as billPath.GetAncestor(1) persisted,
descr varchar(50) not null);
Si nunca ha trabajado con tipos de datos según Microsoft® .NET Framework, la llamada de métodos en la definición de parentBillPath puede parecer inhabitual. La capacidad de invocar un método definido según el tipo y pasarle opcionalmente uno o más parámetros, simplifica en gran medida el código.
Aquí puede ver el método GetAncestor del tipo HierarchyID. HierarchyID almacena la ruta de acceso de una forma binaria compacta. No es posible hacer referencia a algún segmento de dicho valor binario y tratarlo como un billID; tampoco es posible capturar directamente algún subsegmento de la ruta de acceso ordenada para una lista. Para ello, puede usar el método GetAncestor. Aquí, el valor de parámetro significa "devolver la ruta de acceso ordenada que termina con el elemento primario de este nodo". El valor de parámetro controla la posición en la jerarquía en la que se produce el truncamiento en la ruta de acceso ordenada. Por tanto, aquí tiene la ruta de acceso ordenada al elemento primario de la lista actual. La Figura 7 resume los métodos disponibles en el tipo de datos HierarchyID y algunos casos de uso típicos para cada método.
|
METODO
|
DEVOLUCIONES
|
VALORES DE PARAMETRO
|
PROPOSITO
|
|
GetAncestor
|
HierarchyID que representa una ruta de acceso ordenada para un elemento primario o de nivel superior.
|
Entero que indica el número de niveles por encima del nivel para atravesar hacia arriba en la ruta de acceso ordenada actual.
|
Encuentra el elemento primario, el elemento primario principal o el elemento de nivel superior en la ruta de acceso ordenada para esta instancia.
|
|
GetDescendent
|
HierarchyID que representa la ruta de acceso de un elemento secundario, un elemento inferior o un elemento secundario posterior del nodo actual.
|
Dos instancias de HierarchyID, de las cuales una o ambas pueden ser nulas, que restringen el elemento secundario potencial devuelto.
|
Obtiene una ruta de acceso para insertar un elemento nuevo en alguna profundidad en la ruta de acceso ordenada principal.
|
|
GetLevel
|
Valor entero de 16 bits que representa la profundidad total de la ruta de acceso ordenada.
|
Ninguno.
|
Determina si dos rutas de acceso ordenadas tienen la misma profundidad.
|
|
GetRoot
|
HierarchyID para una ruta de acceso ordenada con elementos cero.
|
Ninguno.
|
Encuentra la raíz absoluta para cualquier ruta de acceso ordenada.
|
|
IsDescendantOf
|
1 si la ruta de acceso ordenada pasada como parámetro es un elemento secundario de la instancia de llamada.
|
Una instancia de HierarchyID.
|
Determina si un HierarchyID determinado es un elemento secundario de otra instancia.
|
|
Parse
|
Una instancia de HierarchyID.
|
La representación textual de una ruta de acceso ordenada
|
Crea una instancia de HierarchyID a partir de una ruta de acceso determinada. Se llama implícitamente siempre que una instancia de HierarchyID se establece en una cadena.
|
|
GetReparentedValue
|
HierarchyID que representa una ruta de acceso ordenada completada al mover el elemento actual de una ruta de acceso a otra.
|
La ruta de acceso ordenada actual como un HierarchyID y la ruta de acceso ordenada dirigida, también como un HierarchyID
|
Mueve uno o más valores de fila de una ruta de acceso ordenada de elemento principal a otra.
|
|
ToString
|
La representación textual de una ruta de acceso ordenada de HierarchyID.
|
Ninguno.
|
Analiza la ruta de acceso ordenada de un HierarchyID.
|
Figura 7.
A continuación, debe crear una clave principal en la tabla nueva así como su restricción de clave externa:
<MTJ_C&P_17>
alter table dbo.bill2
add constraint pkBill2
primary key(billPath);
alter table dbo.bill2
add constraint fkBill2Parent
foreign key (parentBillPath) references dbo.bill2(billPath);
En este caso, uso valores de HierarchyID como clave principal y clave externa. Recuerde que un HierarchyID representa una ruta de acceso ordenada primero en profundidad. Por lo tanto, los valores variarán más entre iguales y menos entre una ruta de acceso de elemento primario y secundario. Cuando se usa un valor de HierarchyID para el índice clúster de una tabla, los nodos de la misma ruta de acceso se almacenarán de manera más cercana entre sí que los nodos de otras rutas de acceso. En muchos casos, se trata de un buen diseño ya que se debería poder consultar una ruta de acceso determinada para todos sus elementos secundarios. Sin embargo, si consulta con mayor frecuencia nodos específicos, es recomendable crear el índice clúster en una columna derivada de GetLevel.
Esta implementación concreta presenta un problema sutil. Debido a que una restricción de clave externa se basa en una ruta de acceso en lugar de un valor, se necesita un valor existente en la tabla en la que establecer el delimitador. Todas las cadenas de listas requerirán un delimitador y, afortunadamente, todos pueden usar el mismo. El método GetRoot de HierarchyID es, en realidad, la manera perfecta de resolver este problema. Considere la instrucción siguiente:
<MTJ_C&P_18>
insert into dbo.bill2(billPath,billID,descr)
values (hierarchyID::GetRoot(),0,'All Bills');
Aquí, se crea una lista que representa la raíz más elevada posible en cualquier jerarquía al llamar al método GetRoot como miembro constante del tipo. Ahora, cuando se insertan nodos de primer nivel, todavía harán referencia a un elemento primario dentro de la tabla actual.
Por tanto, ¿cómo se migran las listas existentes de dbo.bill a dbo.bill2? Todo lo que tiene que hacer es modificar la consulta anterior que selecciona la ruta de acceso de la jerarquía para que convierta dicha ruta de acceso en un HierarchyID e inserte los datos en dbo.bill2. A continuación se muestra el código de T-SQL:
<MTJ_C&P_19>
with c(billID,[path],[descr]) as (
select b.billID,'/'+CAST(b.billID as varchar(max)),descr
from dbo.bill b
where parentBillID is null
union all
select b.billID,c.path+'/'+CAST(b.billID as varchar(max)),b.descr
from dbo.bill b
join c on b.parentBillID = c.billID)
insert into dbo.bill2(billpath,billID,descr)
select path+'/' as [path],billID,descr
from c
order by c.path;
La Figura 8 muestra el contenido de dbo.Bill2.
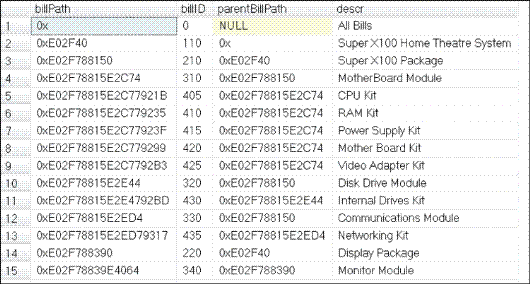
Figura 8. Las 15 primeras filas de dbo.bill2.
Además, ahora es recomendable actualizar la relación de clave externa con dbo.BillPartList de la siguiente manera:
<MTJ_C&P_20>
alter table dbo.billPartList
drop constraint fkBillPartList_Bill
go
alter table dbo.billPartList
add constraint fkBillPartList_Bill2
foreign key(billPath)
references dbo.bill2(billPath)
on delete cascade
on update no action;
Prueba de la implementación de HierarchyID
Con las tablas creadas y rellenadas, y con las restricciones aplicadas, puedo volver a escribir las consultas de prueba anteriores para usar el nuevo tipo HierarchyID. La primera consulta produjo una lista jerárquica de las listas de modo descendente (a partir de la lista 110) mediante una expresión de tabla común recursiva. Cuando uso el tipo de datos HierarchyID, el linaje completo de cualquier lista determinada ya se representa dentro de dicho valor. Por ejemplo, una de las últimas listas de la jerarquía es la lista 405, que representa un kit de CPU. ¿Cómo se puede saber qué listas componen su linaje? Este código lo indicará:
<MTJ_C&P_21>
select billPath.ToString() from dbo.bill2 where billID=405;
El resultado de esta consulta es una cadena con el valor "/110/210/310/405". Ahora la pregunta es ¿cómo se pueden obtener exactamente las listas representadas por dicha cadena? Esto resulta un poco más complicado, ya que el tipo HierarchyID no ofrece ningún método para convertir la lista de valores en un vector. Sin embargo, se puede escribir un método propio mediante T-SQL o SQL/CLR. A continuación se incluye el código para ello mediante una función con valores de tabla de T-SQL:
<MTJ_C&P_22>
create function dbo.Vectorize(@i hierarchyID)
returns @t table (position int identity(1,1)
not null,nodeValue int not null)
as begin
declare @list varchar(max) = @i.ToString();
declare @delimit int;
set @list = substring(@list,2,len(@list)-1);
while len(@list) > 1 begin
set @delimit = charindex('/',@list);
insert into @t values (cast(substring(@list,1,@delimit-1) as int));
set @list = substring(@list,@delimit+1,len(@list));
end;
return;
end;
Ahora dispone de una manera sencilla de examinar el linaje de cualquier lista en el sistema con una sola consulta no recursiva:
<MTJ_C&P_23>
declare @anyBill int = 405;
select b1.billPath,b2.billID,b2.descr from dbo.bill2 b1
cross apply dbo.vectorize(b1.billPath) p
join dbo.bill2 b2 on b2.billID = p.nodeValue
where b1.billID = @anyBill;
¿Cómo se buscan las partes usadas por una lista determinada? A diferencia de la implementación anterior en la que se debe consultar de manera recursiva el listado de listas, esta consulta puede sacar partido de la capacidad de un HierarchyID de determinar si una ruta de acceso ordenada es un descendiente de otra ruta mediante el método IsDescendantOf:
<MTJ_C&P_24>
declare @anyBill int = 110;
declare @sourceBillPath hierarchyID;
select @sourceBillPath = billPath from dbo.bill2 where billID = @anyBill;
select p.partID as 'partID',
p.descr 'partName'
from dbo.bill2 b2
left join dbo.billPartList bpl on b2.billID = bpl.billID
left join dbo.partList pl on bpl.partListID = pl.partListID
left join dbo.part p on pl.partID =p.partID
where b2.billPath.IsDescendantOf(@sourceBillPath)=1
and p.partID is not null
order by p.partid;
El cálculo del MSRP del sistema completo o de cualquier sublista se puede realizar con algunas modificaciones a la técnica que he demostrado anteriormente:
<MTJ_C&P_25>
declare @anyBill int = 110;
declare @sourceBillPath hierarchyID;
select @sourceBillPath = billPath
from dbo.bill2 where billID = @anyBill;
select SUM(p.cost * pl.quantity)*2.0
from dbo.bill2 b2
left join dbo.billPartList bpl on b2.billID = bpl.billID
left join dbo.partList pl on bpl.partListID = pl.partListID
left join dbo.part p on pl.partID =p.partID
where b2.billPath.IsDescendantOf(@sourceBillPath)=1;
La determinación de qué listas usan una parte concreta se puede consultar mediante el método GetAncestor. Dicho método permite consultar una jerarquía de manera ascendente. Aquí, se debe usar la recursión para subir por el listado de listas:
<MTJ_C&P_26>
declare @partID int = 20;
with c(billPath,descr) as (
select b.billPath,b.descr
from dbo.part p
join dbo.partList pl on p.partID = pl.partID
join dbo.billPartList bpl on pl.partListID = bpl.partListID
join dbo.bill2 b on bpl.billID = b.billID
where p.partID = @partID
union all
select b.billPath,b.descr
from dbo.bill2 b
join c on b.billPath = c.billPath.GetAncestor(1))
select distinct descr,billPath
from c
where billPath <> hierarchyID::GetRoot()
order by billPath;
El código de <MTJ_C&P_13> ha insertado una nueva parte y lista. No se necesita realizar ningún cambio en el código para insertar la parte ni para crear la lista de partes. Sin embargo, la creación de una lista proporciona la oportunidad de usar los métodos GetDescendant y GetReparentedValue de HierarchyID. Puedo empezar el proceso con el siguiente extracto de código:
<MTJ_C&P_27>
begin
begin transaction
declare @mp int;
declare @mpl int;
select @mp = MAX(partID)+10 from dbo.part;
insert into dbo.part(partID,descr,cost)
output inserted.*
values (@mp,'4GB USB 2.0 Memory Stick',20.0);
select @mpl = MAX(partListID)+10 from dbo.partList;
insert into dbo.partList(partListID,partID,quantity)
output inserted.*
values (@mpl,@mp,1);
Con la parte y la lista de partes creadas, ahora se crear la lista de materiales relacionada. La idea es insertar la nueva lista en la jerarquía a la derecha de todas las demás listas que componen el Super X100 Home Theatre System. Para ello, tengo que saber dos cosas: la ruta de acceso para la lista primaria y la ruta de acceso para su elemento secundario situado en el extremo derecho.
La ruta de acceso para la lista primaria se obtiene mediante una consulta sencilla. Buscar su elemento secundario del extremo derecho requiere el uso de los métodos IsDescendantOf y GetLevel, tal como se indica a continuación:
<MTJ_C&P_28>
declare @root hierarchyID;
declare @newBillPath hierarchyID;
declare @newBillID int;
select @root = billPath
from dbo.bill2
where billID = 110;
select @newBillPath = max(billPath)
from dbo.bill2
where billPath.IsDescendantOf(@root) =1
and billPath.GetLevel() = @root.GetLevel()+1;
Busco todos los descendientes inmediatos del nodo raíz. Puesto que las rutas de acceso se ordenan por valor, la lista con el valor máximo para el HierarchyID será la instancia situada en el extremo derecho. Al conocer el nodo de igual situado en el extremo derecho, se debe crear una ruta de acceso nueva adyacente a él. Aquí es donde se usa GetDescendant. Los parámetros para este método controlan la ubicación en la que se creará la nueva ruta de acceso. Cuando dejo el segundo parámetro de la lista nulo, quiero indicar que el nodo se debe crear a la derecha del primer parámetro:
<MTJ_C&P_29>
select @newBillPath =@root.GetDescendant(@newBillPath,null);
Ahora tengo una ruta de acceso para la nueva lista que tendrá un valor para newBillID, por lo que sólo hará falta extraer dicho valor. La función con valores de tabla agregada anteriormente puede ayudar:
<MTJ_C&P_30>
select @newBillID = nodeValue
from dbo.Vectorize(@newBillPath)
where position = @newBillPath.GetLevel();
Por último, puedo terminar esta transacción al insertar la lista nueva en la tabla dbo.bill2 e insertar billID y partListID en la tabla dbo.billPartList:
<MTJ_C&P_31>
insert into dbo.bill2
output inserted.*
values (@newBillPath,@newBillID,'Summer Bonus Package');
insert into dbo.billPartList(billID,partListID)
output inserted.*
values (@newBillID,@mpl);
commit;
end;
Para convertir la lista Summer Bonus de un elemento secundario directo del Super X100 Home Theatre System en un elemento secundario de la lista Disk Drive Module no es especialmente difícil, siempre y cuando no se necesite cambiar el billID (consulte <MTJ_C&P_32>). Lo importante de recordar acerca del uso de GetReparentedValue es que su invocación no afecta de por sí a ningún cambio en los valores guardados de una tabla. En cambio, se debe usar una actualización para afectar a dicho cambio.
<MTJ_C&P_32>
Desplazamiento de una lista.
begin
begin transaction
declare @oldPath hierarchyID,@newRoot hierarchyID;
declare @newPath hierarchyID;
declare @billIDToMove int = 251;
declare @billIDToMoveTo int = 320;
select @oldPath = billPath
from dbo.bill2 where BillID = @billIDToMove;
select @newRoot = b.billPath
from dbo.bill2 b where billID = @billIDToMoveTo
select @newPath = @oldPath.GetReparentedValue(
@oldPath.GetAncestor(1),@newRoot);
update dbo.bill2
set billPath = @newPath
output inserted.*
where billID = 251;
commit;
end;
La eliminación de una parte y sus listas de matchingID correspondientes puede ser un proceso bastante sencillo, o bien puede requerir un esfuerzo sustancial. Depende mucho de si la lista que se esté eliminando es el elemento primario de otra lista. Si no lo es, tal como en el caso de la lista Summer Bonus, basta con eliminar la lista de materiales y la parte:
<MTJ_C&P_33>
begin
declare @partToDelete int = 45;
begin transaction
delete from dbo.bill2 where billID in
( select billID from dbo.billPartList bpl
join dbo.partList pl on bpl.partListID = pl.partListID
join dbo.part p on pl.partID = p.partID
where p.partID = @partToDelete);
delete from dbo.part where partID = @partToDelete;
commit;
end;
La eliminación de una lista que es el elemento primario de una o más listas distintas en un diseño como el que se presenta aquí requiere código más complejo. El problema es que existe una restricción de clave externa que requiere que cada lista tenga un elemento primario inmediato. Si intento eliminar una lista primaria, se generará un error. Para corregir esto, debo mover primero cualquier elemento secundario a una lista que sobrevivirá. Para ello, se deberá descartar temporalmente la restricción de clave externa y calcular rutas de acceso para los nodos nuevos mediante el método GetReparentedValue.
Conclusión
El nuevo tipo HierarchyID de SQL Server 2008 ofrece tipos de datos compactos con la capacidad de almacenar y trabajar con rutas de acceso ordenadas que identifican nodos. Casi cualquier sistema que depende de un modelo jerárquico de datos se puede implementar usando este nuevo tipo de datos.
Los principales beneficios son que se puede reducir la cantidad de datos almacenados físicamente en el disco y escribir consultas menos complejas. Tenga en cuenta que todavía puede aprovechar también la compatibilidad de SQL Server nativa para colocar en cascada restricciones de integridad referenciales con este tipo. El punto clave de recordar es que, a diferencia de métodos tradicionales para el modelado de una jerarquía mediante valores de escala para el identificador de un elemento secundario y el identificador de un elemento primario, con HierarchyID cada nodo contendrá su ruta de acceso completa como su identidad.