Ahora bien, entre estas instrucciones hay diferencias de performance a favor del UNION ALL por lo cual la recomendación es tratar de usar esta sintaxis siempre que se pueda y evitar el uso solo de UNION. Obviamente habrá casos donde necesitamos eliminar duplicados pero esto no es común, muchas veces nos encontramos código con UNION donde se podía usar tranquilamente UNION ALL, sea por una cuestión de comodidad al escribirlo o desconocimiento del impacto negativo en la performance.
Veamos una comparación de estas dos instrucciones. Lo primero que haremos es crear dos tablas:
USE TEMPDB
GO
CREATE TABLE T1 (
DESCRIPCION VARCHAR(50)
)
GO
CREATE TABLE T2 (
DESCRIPCION VARCHAR(50)
)
GO
Luego le insertamos algunos datos:
INSERT INTO T1 (DESCRIPCION)
VALUES ('UNO')
INSERT INTO T1 (DESCRIPCION)
VALUES ('DOS')
INSERT INTO T1 (DESCRIPCION)
VALUES ('TRES')
INSERT INTO T1 (DESCRIPCION)
VALUES ('CUATRO')
INSERT INTO T1 (DESCRIPCION)
VALUES ('CINCO')
INSERT INTO T2 (DESCRIPCION)
VALUES ('UNO1')
INSERT INTO T2 (DESCRIPCION)
VALUES ('DOS1')
INSERT INTO T2 (DESCRIPCION)
VALUES ('TRES1')
INSERT INTO T2 (DESCRIPCION)
VALUES ('CUATRO1')
Ahora que tenemos nuestras dos tablas haremos las querys de UNION y luego UNION ALL comparando sus query plan:
SELECT * FROM T1
UNION
SELECT * FROM T2
El costo total de esta query es de 0,017.
Aquí podemos observar una operación Sort que consume el 63% del query plan y la cual se debe aplicar para los Distinct ya que se deben eliminar duplicados.
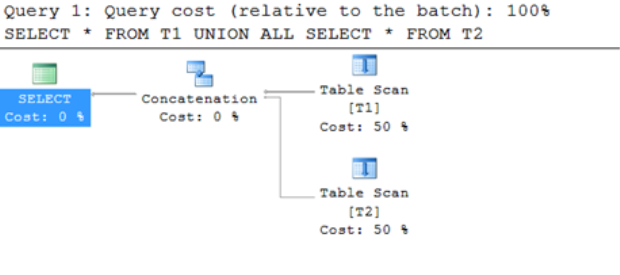
Ahora ejecutaremos la misma query pero con UNION ALL.
SELECT * FROM T1
UNION ALL
SELECT * FROM T2
 Aquí su costo es de 0,0065, si comparamos ambos query plan observamos este cambio.
Aquí su costo es de 0,0065, si comparamos ambos query plan observamos este cambio.
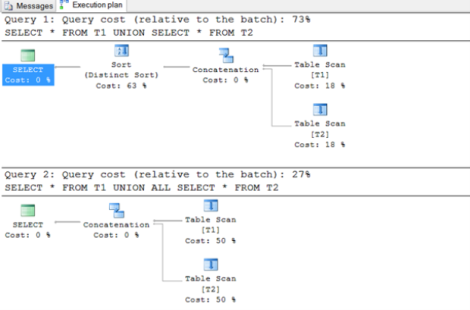
En el primero tenemos un mayor consumo ya que se debe aplicar el distinct y en el segundo no.
El resultado de la consulta en ambos casos da los mismos registros.
Como resumen recomiendo no aplicar por defecto el uso de UNION y solo dejarlo para casos donde no se necesiten duplicados, y si utilizar más el uso de UNION ALL ya que como hemos podido observar es más performante.